Компьютерные технологии обработки речевых сообщений.
Женило В.Р.Начало - Фонограмма - След - Спектр - Речь - Фоноскопия - Вопросы ![]()
![]()
![]() Компьютерная фоноскопия
Компьютерная фоноскопия
![]()
![]() Анализ и синтез речевых сигналов по отдельным элементарным компонентам
Анализ и синтез речевых сигналов по отдельным элементарным компонентам
В разделах "Спектральный анализ следов звука", "Голосовой импульс, форманты, высота голоса, речевой сигнал", "Анализ артикуляционных особенностей говорящего" и "Анализ голосовых особенностей говорящего" говорилось о том, что в зависимости от того, следы каких объектов (фонообъектов) или явлений нам требуется визуализировать в первую очередь (ярче или четче всего), используются широкополосные или узкополосные сонофильмы. Выбор одного из этих типов сонофильма определяется тем, удается ли расслоить отдельные следы интересуемых звуковых объектов. Когда основная задача заключается, например, в очистке речи от нежелательных помех или наслоения других мешающих или полностью заглушающих речь звуки, то обычно выбирают узкополосные сонофильмы.
Удаление из речевого сигнала следов иных фонообъектов, мешающих правильному восприятию речи или снижающих качество ее звучания, - достаточно актуальная задача. К сожалению, для ее решения многие методы фильтрации иногда оказываются недостаточно эффективными. Особо остро этот вопрос стоит в криминалистике, требующей сохранения аутентичности следов исследуемых фонообъектов на всех этапах исследования, и в частности на этапе очистки речевого сигнала от шумов и помех.
В настоящее время все системы фильтрации речевых сигналов, доступные экспертам-криминалистам, обладают одним весьма негативным свойством. Все они так или иначе искажают следы фонообъектов, по которым эксперт в последующем принимает решение по тому или иному вопросу экспертизы.
В этой связи в Экспертно-криминалистическом центре МВД России были проведены специальные исследования (Тимофеев И.Н., Голощапова Т.И., Докучаев И.В.. Возможности использования средств многоканальной шумоочистки сигнала при проведении идентификационных исследований: Тезисы докладов Международной конференции "Информатизация правоохранительных систем". – М.: Академия управления МВД России, 1997. С. 194 - 196) по определению того, какие системы фильтрации сигналов для повышения разборчивости речи могут использоваться для очистки следов речи от шумов, помех и наслоений следов иных фонообъектов, а какие - нет. Оказалось, что практически все имеющиеся на рынке системы фильтрации речевых сигналов смещают (искажают) те акустические параметры речевых сигналов, по которым принимаются решения о тождестве следов голоса и артикуляции говорящего, о диагностике и идентификации условий звукозаписи и т.п. Это происходит потому, что изначально цель любых подобных автоматических систем заключается в повышении разборчивости речи, воспринимаемой на слух, любым путем, вплоть до искажения самого речевого сигнала, делающего его совершенно непохожим на натуральный (природный) речевой сигнал.
Почему на это идут разработчики систем очистки речевых сигналов? Да потому, что, бесспорно, задача повышения разборчивости речевых сигналов так же сложна, как и любая другая задача в речевой технологии. И поэтому разработчики этих систем вынуждены идти на определенные жертвы качества получаемого очищенного речевого сигнала. Эта вынужденная мера объясняется спецификой живого речевого сигнала как следа интеллектуального фонообъекта в реальных условиях, со всеми эффектами отражения волн, реверберации, детонации магнитофонов и т.п. Описать такой след речевого сигнала математически с достаточной степенью достоверности априори очень сложно. Поэтому-то разработчики систем повышения разборчивости зашумленной речи и закрывают глаза на возможные изменения ряда качественно важных характеристик отфильтрованного речевого сигнала, ради решения главного вопроса - что сказано в помехах или в шумах.
Хороших систем очистки речевых систем существует мало. Для их создания требуется мощная научная школа, инженерно-техническая и производственные базы. В этом плане в нашей стране особо выделяется “Центр речевых технологий” (ЦРТ). Имея лицензию ФСБ на право разработки и реализации специальных технических средств, ЦРТ производит широкий спектр систем очистки речевых сигналов, начиная от узкоспециализированных и заканчивая системами широкого назначения типа “Золушка-97” и “Икар”. Эти системы впитали в себя весь богатейший арсенал разработчиков всего мира в течение не одного десятки лет. Сложнейшие алгоритмы адаптивной фильтрации речевых сигналов позволяют в автоматическом режиме (в реальном масштабе времени) следить за компонентами сигнала, имеющими заведомо не речевую природу. И настроившись на них, подавлять с заданной силой, повышая тем самым разборчивость слышимой речи. Но при такой автоматической корректировке речевого сигнала последний, как правило, приобретает существенные искажения, затрудняющие дальнейшее его использование в решении экспертно-криминалистических задач.
Вот почему на практике чаще всего складывается примерно следующая ситуация. Чтобы измерить параметры речевых сигналов для проведения идентификационных исследований, требуется предварительно очистить сигналы от помех и шумов. Но после этой процедуры проведение идентификационных исследований по очищенным следам речевых сигналов зачастую становится просто недопустимым.
Выход из данной проблемной ситуации возможен. Он основан на расслоении всех следов фонообъектов, присутствующих в заданном сигнале, на две группы, с последующим восстановлением двух сигналов во временной области таким образом, чтобы каждый из них содержал следы лишь одной группы и, что самое главное, каждый из них оставался аутентичным (подлинным, не искаженным системой обработки данных).
Следует отметить, что в фоноскопии этот подход возможен потому, что до этапа преобразования акустической волны в электрическую (в микрофоне) все акустические сигналы ведут себя как обычные волны, со всеми вытекающими отсюда свойствами, преимуществами и недостатками. Поэтому если, например, в дактилоскопии наложение нового отпечатки пальца, покрытого краской, на старый может полностью закрыть отдельные элементы последнего, то в фоноскопии наложение двух акустических волн (речевых сигналов) приводит к их интерференции (Интерференция волн (от лат. inter – взаимно, между собой и ferio – ударяю, поражаю) - сложение в пространстве двух (или нескольких) волн, при котором в разных его точках получается усиление или ослабление амплитуды результирующей волны. Интерференция характерна для волн любой природы. (Физический энциклопедический словарь)). В фоноскопии если следы нескольких фонообъектов смешиваются, то они "живут" независимо друг от друга, не разрушая друг друга, а лишь интерферируя. И наложение одного следа на другой не уничтожает последний так, как это происходит при наложении нескольких отпечатков пальцев друг на друга.
Представление следов звука с помощью фонофильмов позволяет эксперту визуально различать отдельные частотно-временные компоненты даже нескольких смешанных сигналов - следов разных звуков. Сделать то же самое во временной области с помощью исходной осциллограммы практически невозможно.
Для пояснения принципиальных возможностей технологии разложения речевого сигнала на простейшие гармонические микроволны приведем следующий пример (Графические образы речевых сигналов на рис. 37, 38, 40, 41, 42, 43, 44, 45, 46, 47, 48 получены с помощью компьютерной системы “Voice Extractor” (“Извлечение голоса”), разработанной автором данной главы. Эта компьютерная система, в свою очередь, создавалась с помощью системы программирования “Visual-C” фирмы Microsoft). На рис. 37 показаны узкополосный сонофильм и соответствующая ему диаграмма динамики уровня мощности (громкости) показанного на сонофильме фрагмента речи.
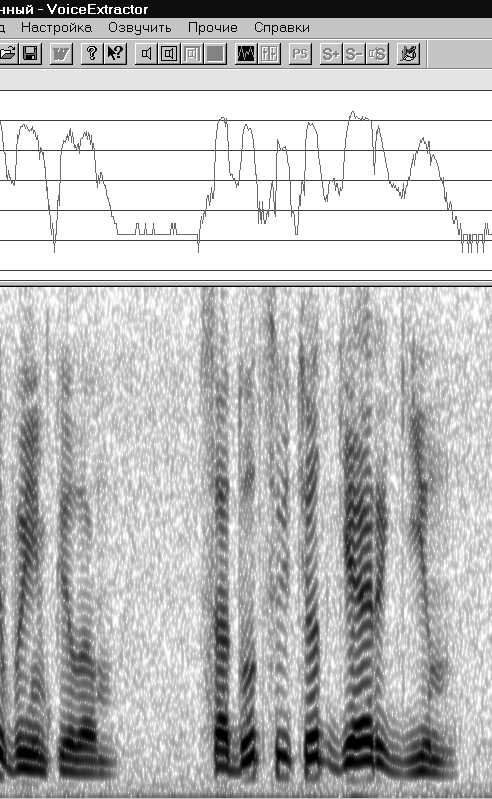
Рис. 37. Уровень мощности и сонофильм исходного речевого сигнала.
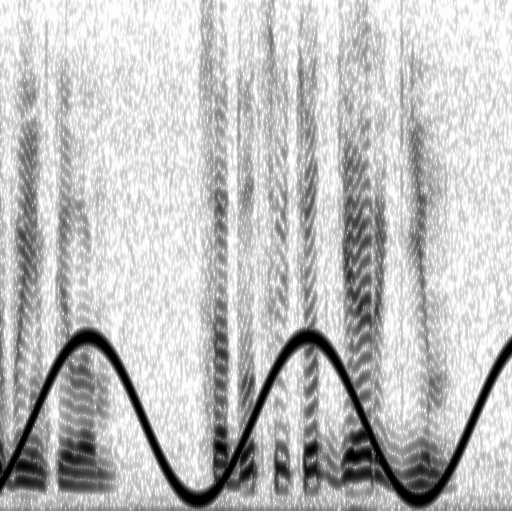
Разложим весь фонофильм на отдельные составные элементы, которые на картинке представлены в виде отдельных точек черного или серого цвета. Каждая точка на фонофильме представляется самостоятельным элементом, который можно удалять, перемещать, усиливать и т.п. Фактически этот мельчайший элемент во временной области (на осциллограмме) имеет вид очень коротенькой микроволны гармонической формы, показанной на рис.
14.Из всех полученных составных элементов речевого сигнала снова соберем уже новый сигнал. Результат этой сборки показан на рис.
38. Новый синтетический сигнал будет очень мало отличаться от своего оригинала. А на слух отличить синтетический сигнал от оригинала может далеко не всякий. Для этого надо иметь очень тонкий слух.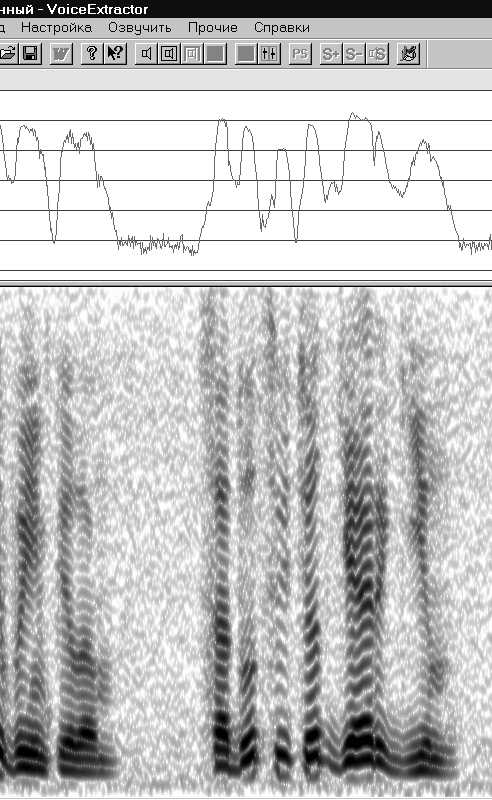
Если присмотреться к различиям между оригинальным речевым сигналом и синтетическим, то можно увидеть, что от оригинального синтетический отличается рисунком шумов, сопутствующих речевому сигналу. Этот рисунок хорошо просматривается в речевых паузах.
Сравнение осциллографической формы описания исходного сигнала (верхняя часть рис.
39) со вновь собранным из микроволновых элементов (нижняя часть рис. 39) так же показывает их хорошее совпадение.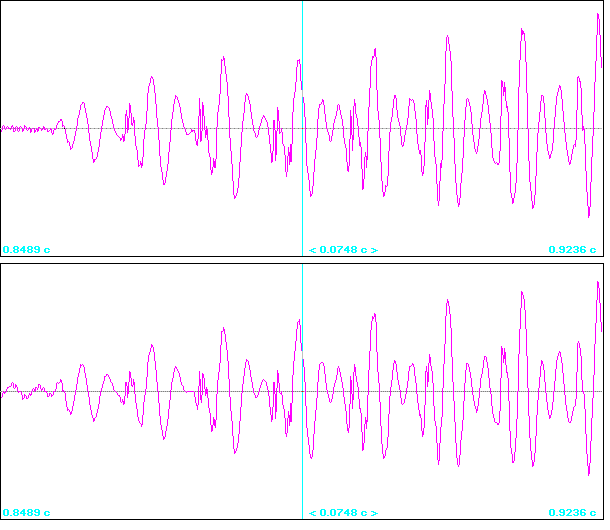
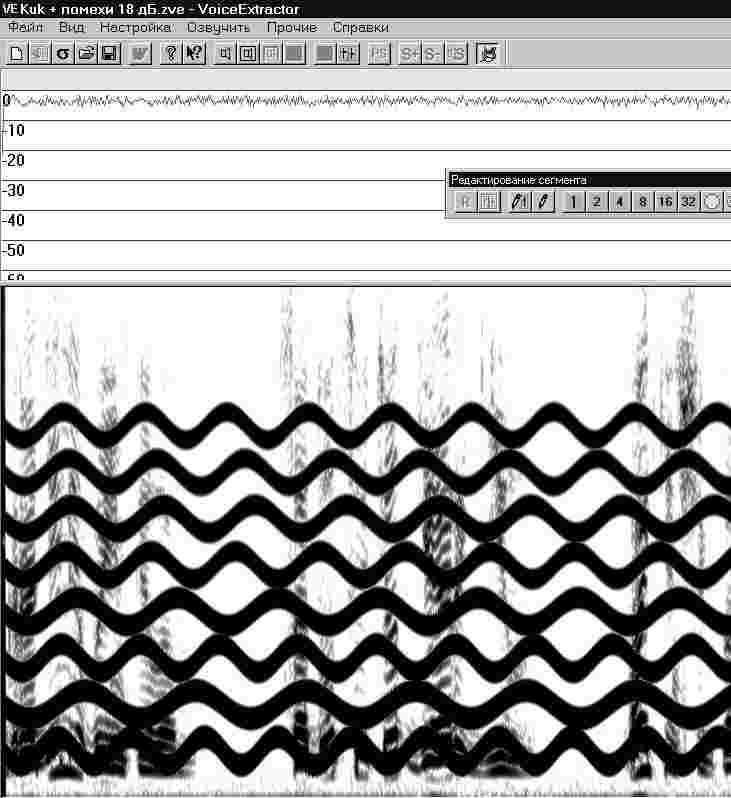
Теперь рассмотрим другой пример. Предположим, что речевой сигнал сопровождает мощная сирена. Уровень мощности помехи слабее самого мощного участка исходного речевого сигнала на 5 дБ. На слух такая речь вполне разборчива, несмотря на присутствие сильно мешающей помехи. Сонофильм такого сигнала показан на рис.
40.
Если в этом сонофильме пометить след сирены и затем удалить его, то получается исходный сигнал. Результат такой компьютерной обработки сигнала показан на рис.
41. На этом рисунке хорошо видно, что удаление помехи прошло очень удачно. Это отразилось в чистоте сонофильма нового обработанного сигнала. В том месте, где находилась помеха, практически не видны никакие ее следы.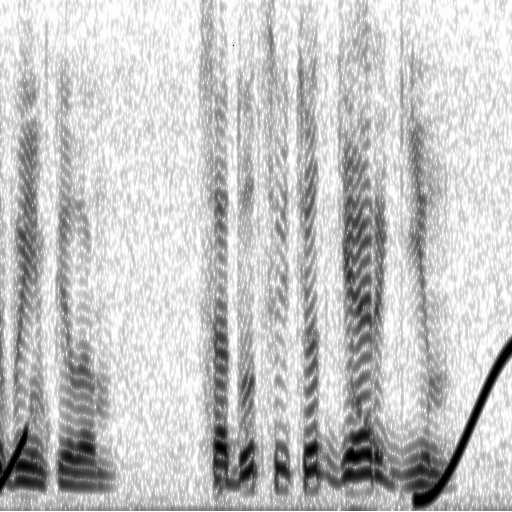
Здесь важно подчеркнуть, что в этом примере сам речевой сигнал не пропускался через весь механизм анализа-синтеза. Не все следы но сонофильме рис.
41 раскладывались на микроволновые элементы и затем собираются снова вместе, а только следы помех. При этом речевой сигнал остался полностью аутентичным (равным оригинальному). Через механизм синтеза были пропущены только следы помех, которые были разложены на микроволновые элементы и вычтены из исходного сигнала.Этот пример хорошо иллюстрирует различие технологий очистки следов в фоноскопии и дактилоскопии. В фоноскопии, убрав микроволновые элементы мощной помехи, можно под ним увидеть (и, значит, услышать) следы полезного сигнала в первозданном (аутентичном) виде. Это принципиально возможно в силу аддитивности акустических сигналов. Поэтому вполне возможно извлечение речевого сигнала из-под ряда мощных гармонических помех, полностью его заглушающих.
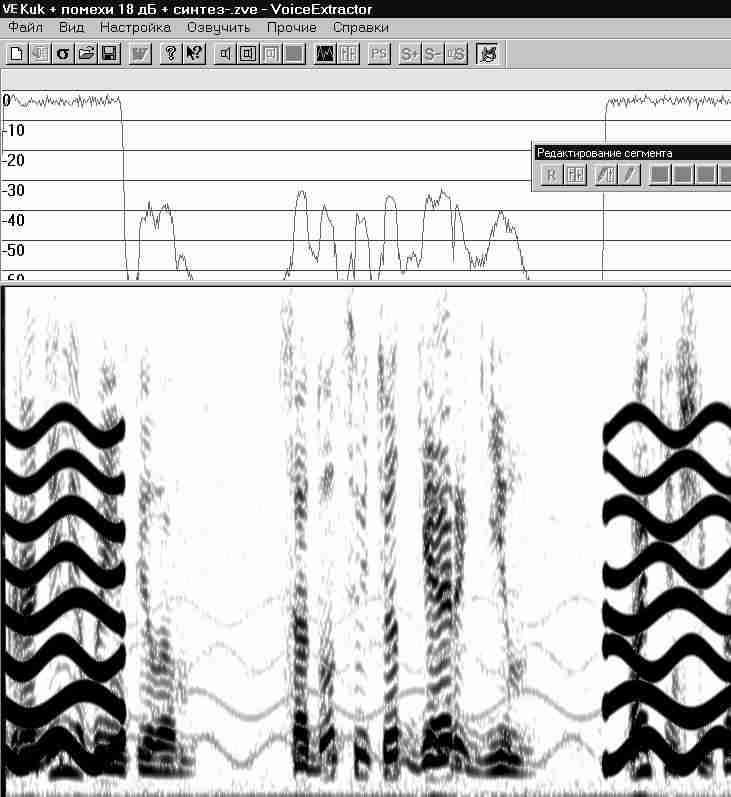
Для иллюстрации сказанного приведем следующий пример извлечения речевого сигнала из смеси частотно-модулированных помех, превышающих самые мощные участки речевого сигнала более чем на 20 дБ. При таких помехах не только нельзя разобрать, что сказано, но нельзя определить – говорилось ли вообще что-нибудь. То есть при таких помехах следы речи вообще не слышны. Сонофильм описанной фонограммы показан на рис.
42.
После выделения на малом участке сигнала следов помех эти следы были автоматически разложены на микроволновые элементы и вычтены из исследуемого сигнала. В результате был получен новый сигнал, уровень мощности и сонофильм которого показаны на рис.
43.
В результате получается сигнал, на очищенном участке которого хорошо слышна речь, разборчивость которой полная, хотя и слышны некоторые дефекты. На обработанном участке сигнала уровень помех снизился примерно на 60 дБ (это очень много). Сравнение сонофольмов на рис.
42 и 43 показывает, что полностью замаскированные следы речи стали видны в обработанном сигнале. При этом, правда, видны некоторые остатки следов помех. Но на слух восстановленная речь полностью разборчива.Следует отметить, что такие результаты могут быть достигнуты лишь в тех случаях, когда следы речевого сигнала реально присутствуют в исследуемом сигнале, а не потеряны в результате сильных нелинейных искажений или когда полезный сигнал слабее помехи более того, что в принципе может зафиксировать аппаратура.
С помощью описанной компьютерной технологии не всегда удается получить такой хороший результат. Например, если та же речь звучит в сильно реверберирующем помещении с мощным эхом, то следы помехи и ее отражения от стен помещения могут оказаться настолько близи друг к другу по частоте, что отделить их друг от друга на сонофильме практически невозможно. Тогда на обработанном сигнале останется много следов помех. Но все равно речь из неразборчивой переходит в разборчивую. Иллюстрация сказанного показана на рис.
44 и 45.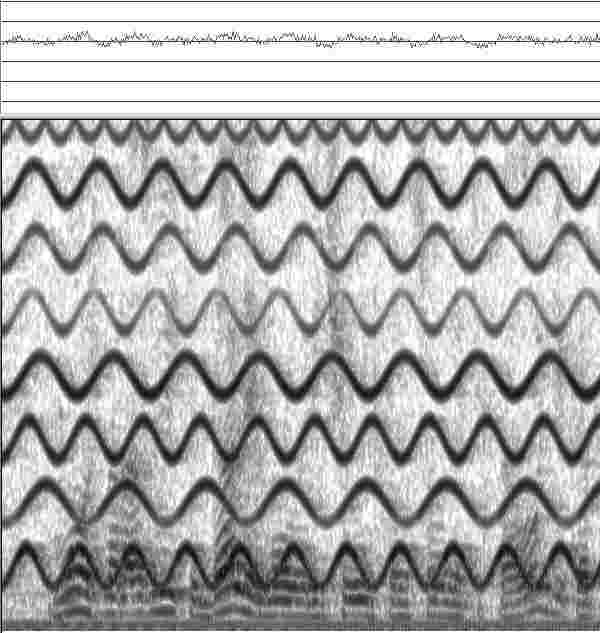
На рис.
45 видно, что не все следы помех удалены за одну операцию. Удаленными оказались только главные компоненты помех, а их отраженные от стен, потолка и пола помещения составные части остались не удаленными.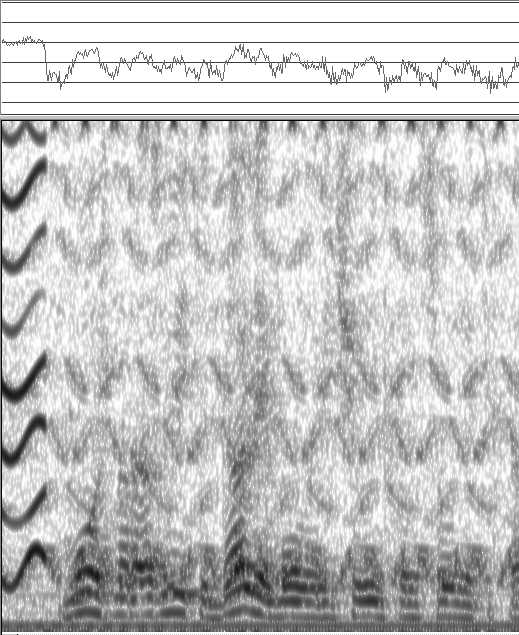
Можно повторно пометить следы оставшихся отраженных волн, разложить их на микроволновые элементы и вычесть их из исследуемого сигнала. Но при этом начинают сказываться ограничения на корректность всех подобных операций, поскольку уровень сигнала помехи уже становится слишком близким к уровню самого речевого сигнала. В таком случае можно по ошибке удалить и следы самого речевого сигнала, в результате чего на сонофильме появятся пустые светлые полосы.
Но следует еще раз подчеркнуть, что на всех остальных участках всех кадров сонофильма следы исследуемого речевого сигнала гарантированно остаются аутентичными, что очень важно для криминалистических фоноскопических исследований и экспертиз.
Описанная технология ранее была в принципе невозможна. Она стала реальной только благодаря современной компьютерной технике.
Начало - Фонограмма - След - Спектр - Речь - Фоноскопия - Вопросы ![]()
![]()